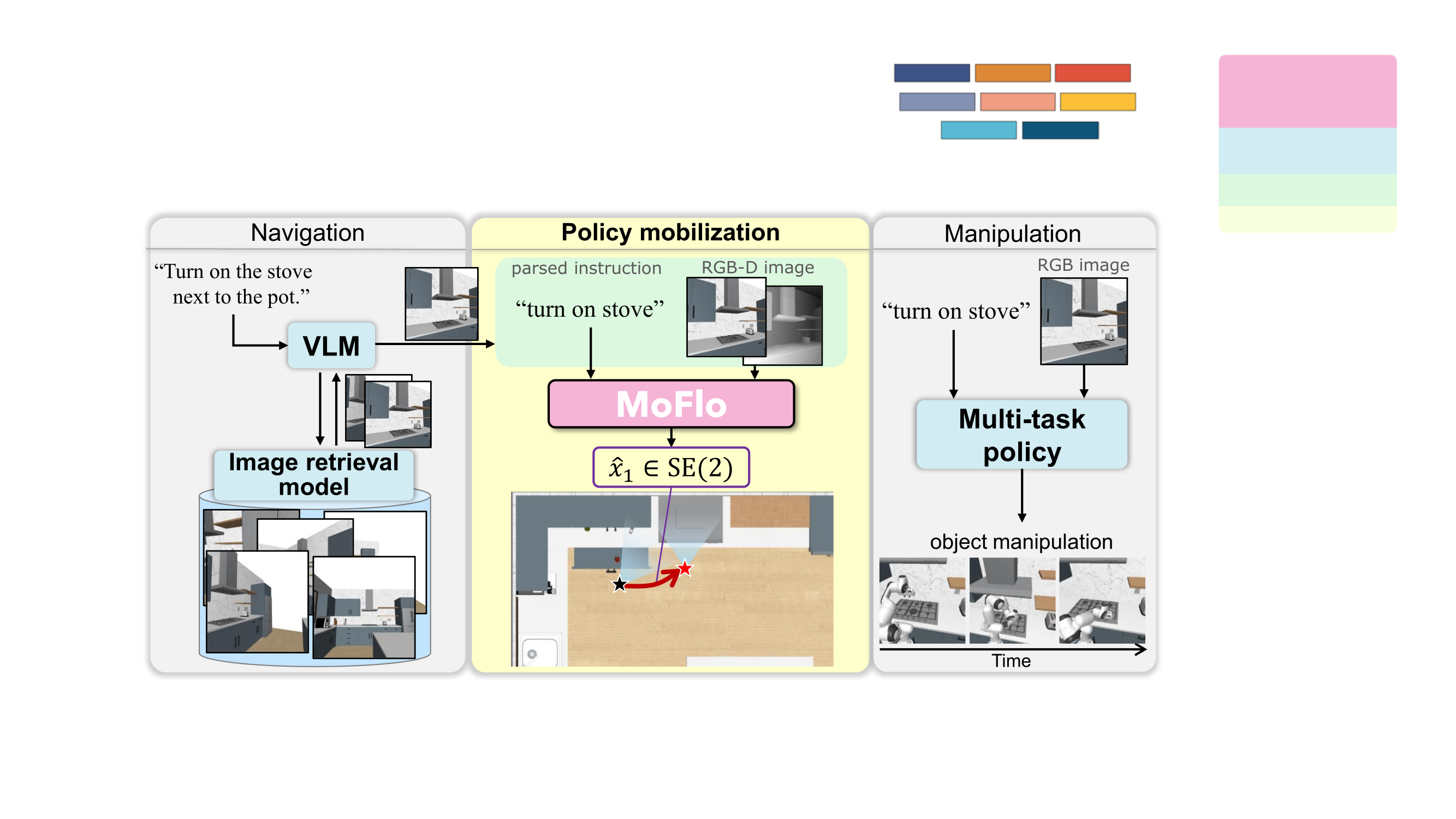
Open-vocabulary mobile manipulation (OVMM) requires a robot to carry out a natural-language instruction on a mobile platform, and the success of learned manipulation policies hinges on placing the base within the policy's training distribution. We focus on policy mobilization, the problem of predicting an \(SE(2)\) base pose from which a fixed pre-trained manipulation policy will succeed, given a single ego-centric RGB-D frame and a language instruction. Prior work estimates a per-task, instruction-agnostic success likelihood over base poses, which limits generalization across tasks and language-based disambiguation. To address these limitations, we propose MoFlo (Mobilization Flow), a multi-task model that learns a language- and observation-conditioned transport from the robot's current base pose to a policy-compatible endpoint, trained by conditional flow matching with \(x_1\) prediction. On five RoboCasa kitchen tasks, MoFlo achieves an 80% mean success rate, outperforming prior policy-mobilization baselines, and further extends to language-based disambiguation among multiple fixtures of the same category. In real-world experiments on a mobile manipulator, MoFlo places the base for successful manipulation from a single ego-centric observation, including cases that require selecting a language-specified target in an ambiguous scene, outperforming a representative baseline.
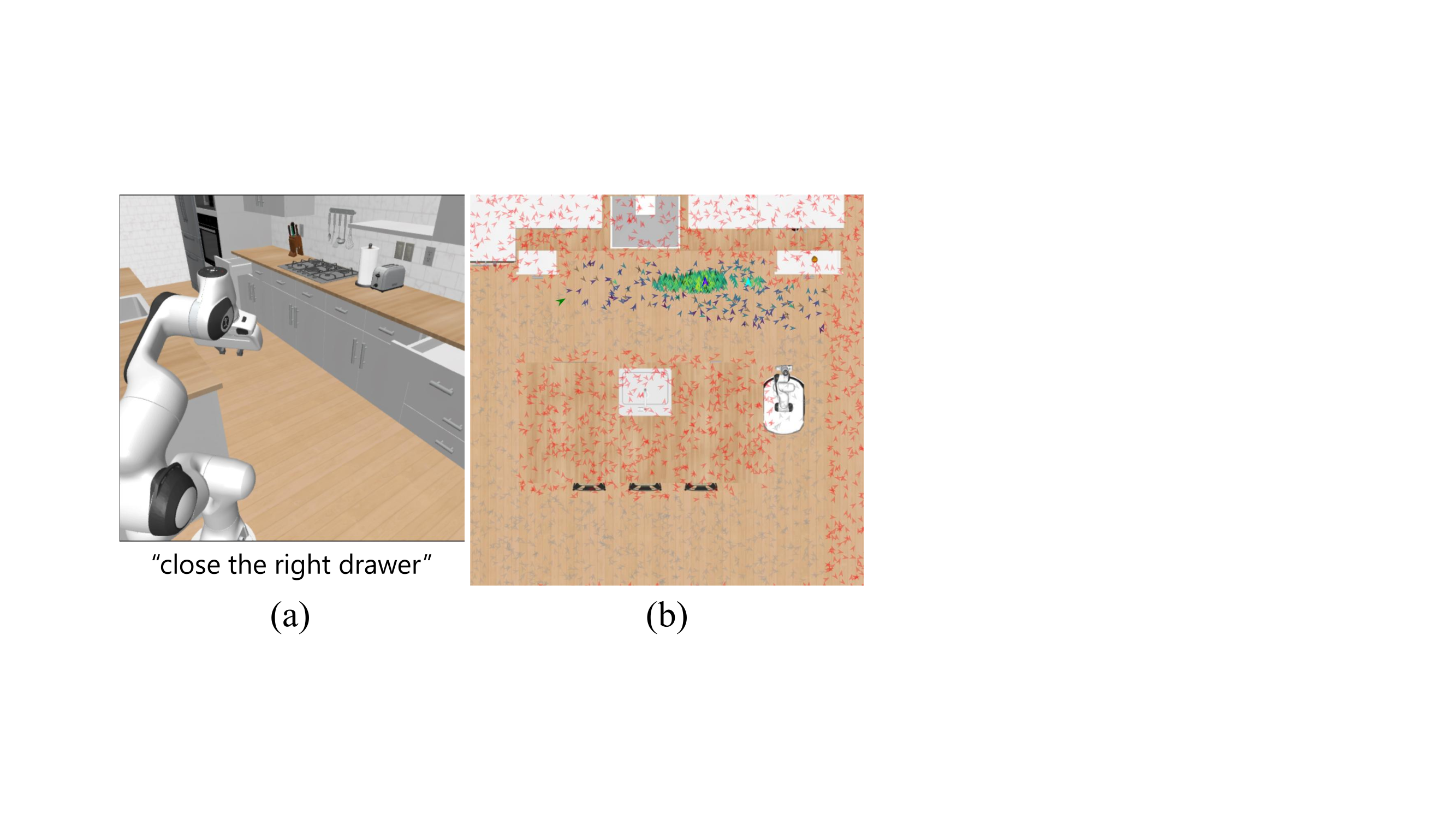
The correct base pose depends jointly on the task, on which target object the instruction names among visually-similar candidates, and on the manipulation policy's own viewpoint distribution. Prior policy-mobilization methods train one pose distribution per task and condition only on the visual scene, so when an instruction such as “close the right drawer” names one of two identical open drawers, an instruction-agnostic baseline assigns pose mass in front of both and cannot resolve which one the prompt refers to. This motivates reformulating policy mobilization as a direct language-conditioned prediction handled by a single multi-task model.
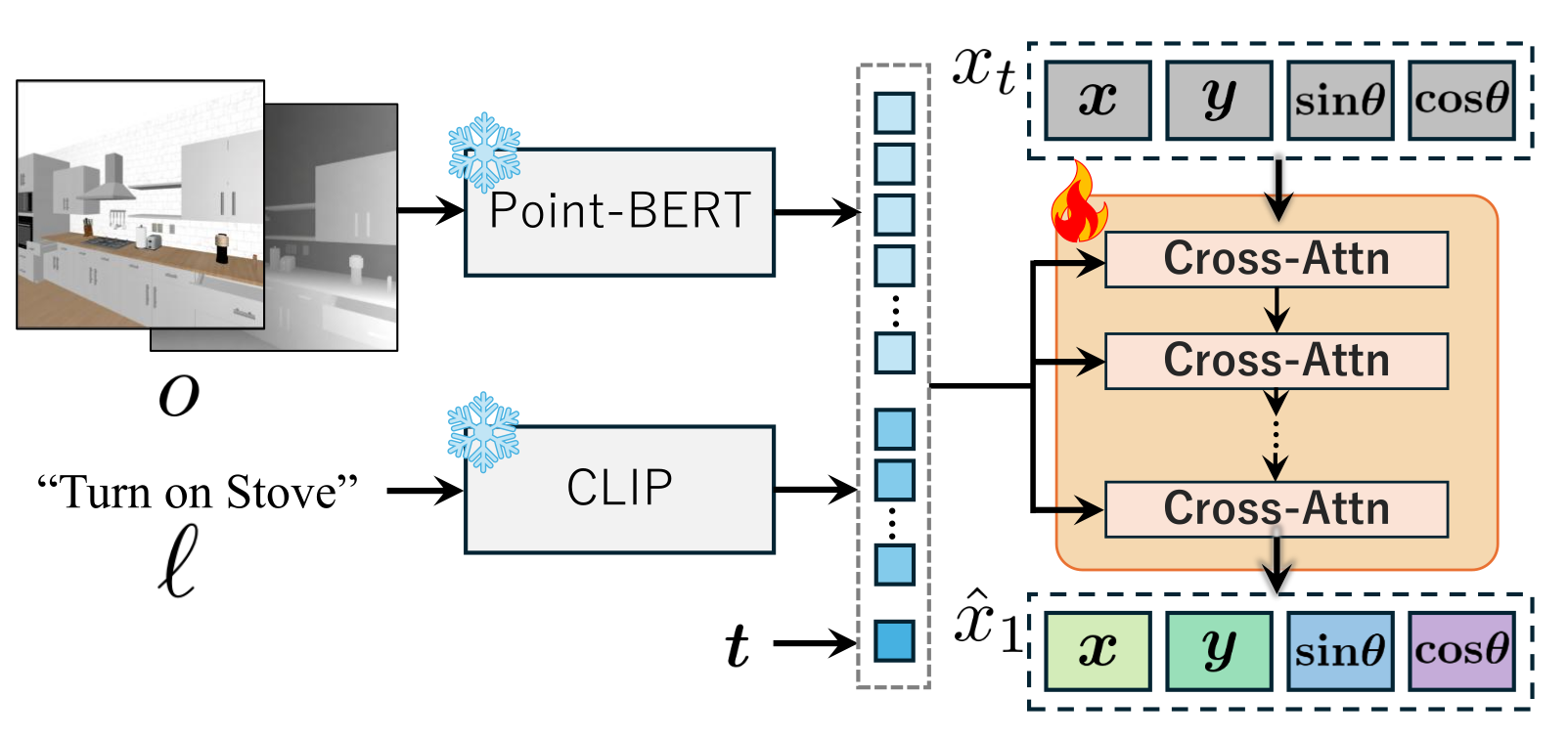
A single ego-centric RGB-D frame and a language instruction are encoded by a frozen Point-BERT visual encoder and a frozen CLIP ViT-B/16 text encoder. The resulting embeddings, together with the robot's current base pose \(x_0=(x,y,\cos\theta,\sin\theta)\), feed a transformer head that predicts the target base pose \(\hat{x}_1 \in SE(2)\). The robot then navigates to \(\hat{x}_1\) and the fixed manipulation policy executes. Inference is a single forward pass — no per-scene reconstruction, candidate-pose sampling, or iterative pose search.
The endpoint prediction is trained with the velocity loss \[ \mathcal{L}(\psi) = \mathbb{E}_{(o,\ell,x_0,x_1),\,t}\!\left[\, w \left\| \frac{\hat{x}_1 - x_t}{1-t} - (x_1 - x_0) \right\|^2 \right], \] where \(x_t = (1-t)\,x_0 + t\,x_1\), \(w\) is a per-sample success weight, and the flow time \(t\) is sampled from a Beta distribution that concentrates supervision near \(t{=}0\) — exactly where the ODE integrator starts at deployment.
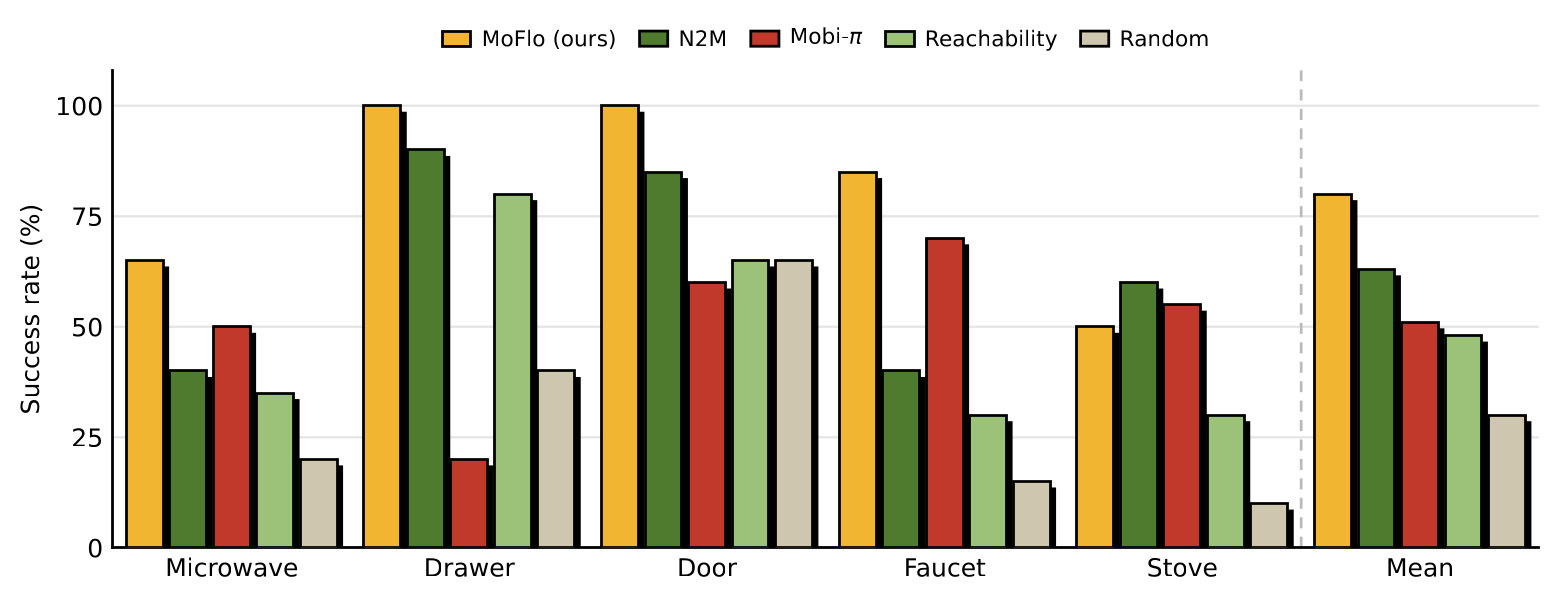
On five RoboCasa kitchen tasks (TurnOnMicrowave, CloseDrawer, CloseSingleDoor, TurnOnSinkFaucet, TurnOnStove; \(n{=}20\) per cell), MoFlo reaches an 80% mean success rate, outperforming all prior policy-mobilization baselines. It improves the mean by 17 points over N2M (63%) and 29 points over the reconstruction-based Mobi-\(\pi\) (51%), achieving the highest success rate on four of the five tasks. All methods are evaluated on the same layouts and object-placement distribution with the fixed downstream manipulation policy.
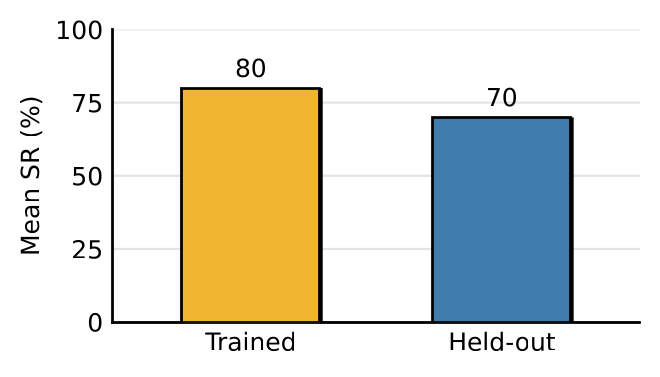
Held-out instruction phrasings. Replacing every training instruction with a paraphrase never seen during training (e.g. “slide the drawer in” for “close the drawer”), MoFlo retains a 70% mean success rate against 80% under trained phrasings — the model acts on instruction content rather than memorizing trained phrasings.
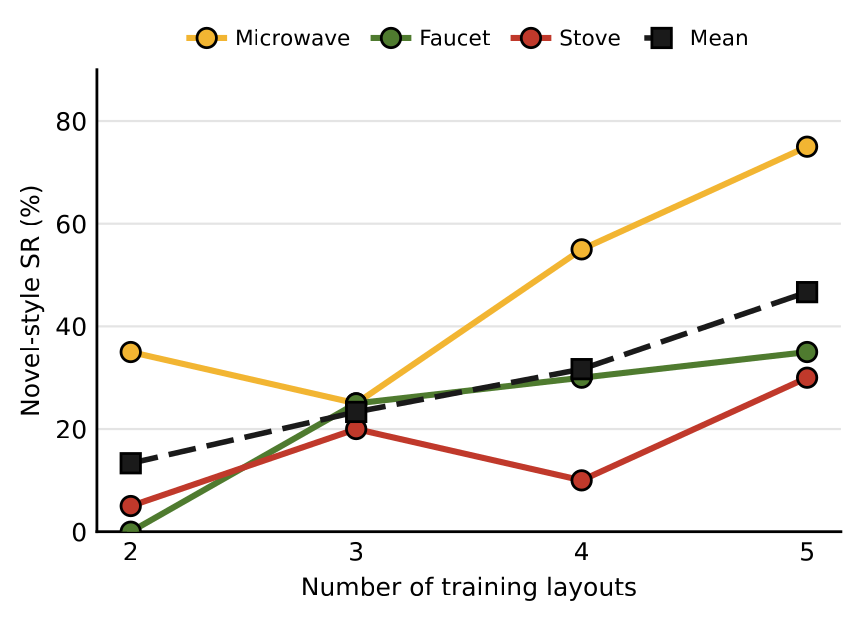
Novel scene appearance under data scaling. Retraining MoFlo on \(N\in\{2,3,4,5\}\) layouts and evaluating each model on the same (seen layout \(\times\) novel style) scene pairs, novel-style success improves overall as the number of training layouts grows. Appearance robustness is bound by data coverage rather than the architecture — adding training kitchens directly buys robustness to appearance shift.
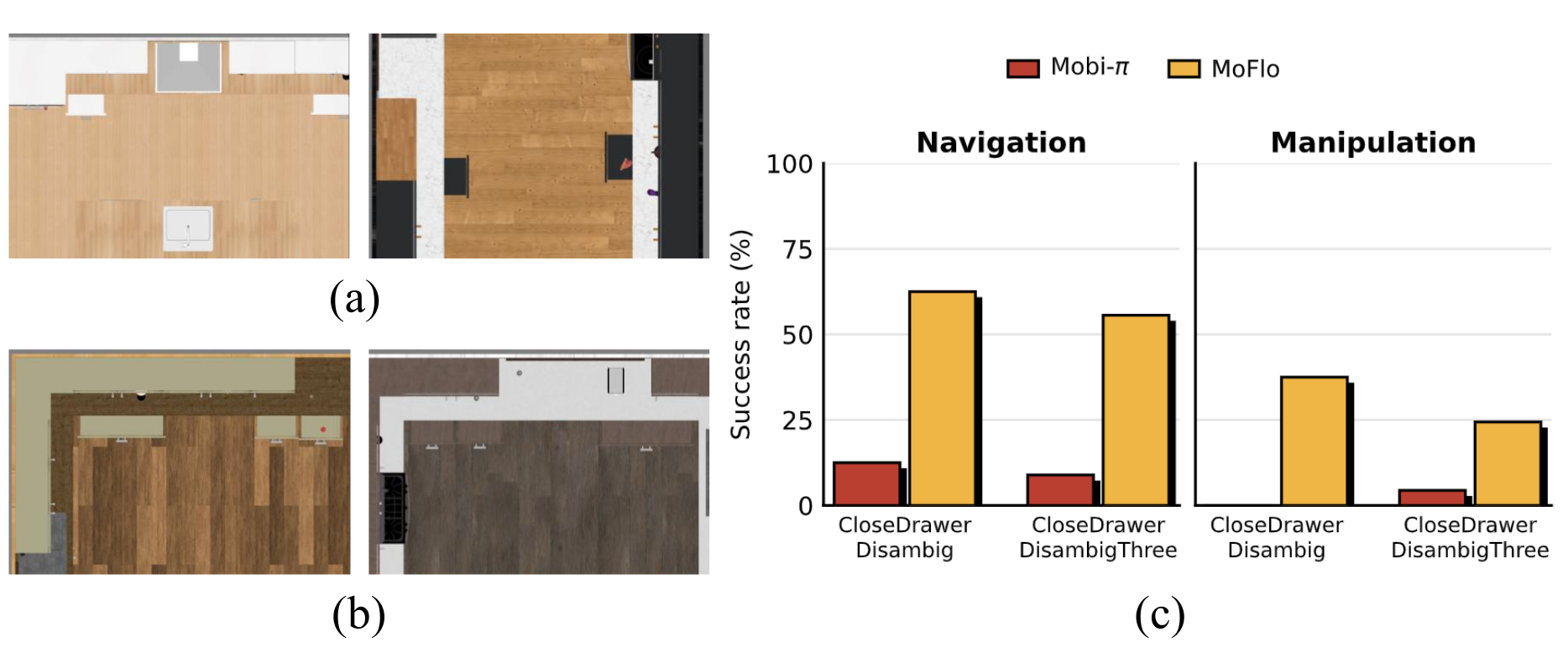
Real OVMM scenes often contain multiple fixtures of the same type. On CloseDrawerDisambig (two open drawers), MoFlo achieves 62.5% navigation and 37.5% manipulation success rate, exceeding Mobi-\(\pi\) by 50.0 and 37.5 points. Applied zero-shot to CloseDrawerDisambigThree (three open drawers), MoFlo reaches 55.6% navigation and 24.4% manipulation success rate, remaining 46.7 and 20.0 points above Mobi-\(\pi\). Language conditioning lets MoFlo select the correct fixture among same-category candidates, which instruction-agnostic methods cannot express by construction.
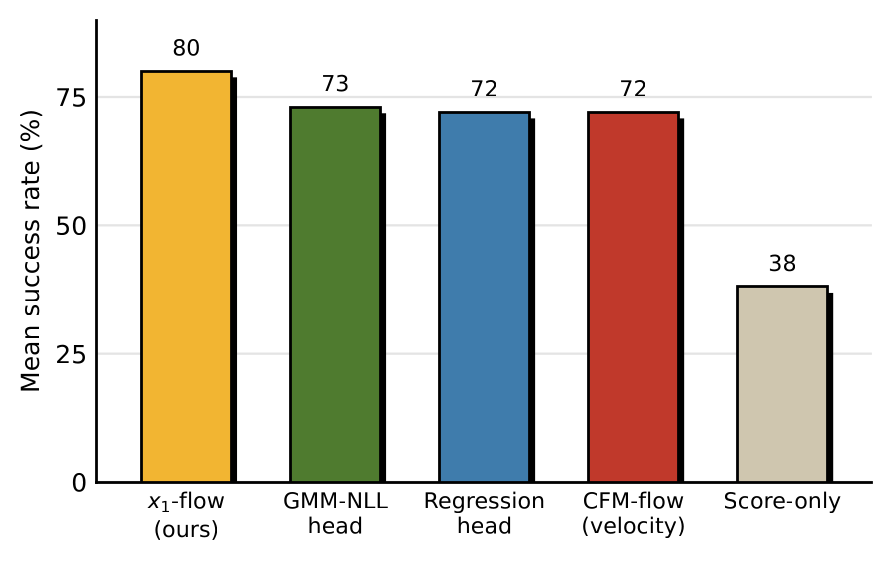
Pose head. The \(x_1\)-prediction head is compared against four alternatives sharing the same encoders, backbone, and language conditioning: N2M's GMM-NLL head, a regression head, a velocity-parameterized flow head, and a score-only variant. The \(x_1\)-prediction head gives the best 5-task mean; the GMM-NLL, regression, and velocity heads fall within 8 points, and the score-only variant trails well behind. Predicting the endpoint rather than the velocity is the decisive choice.
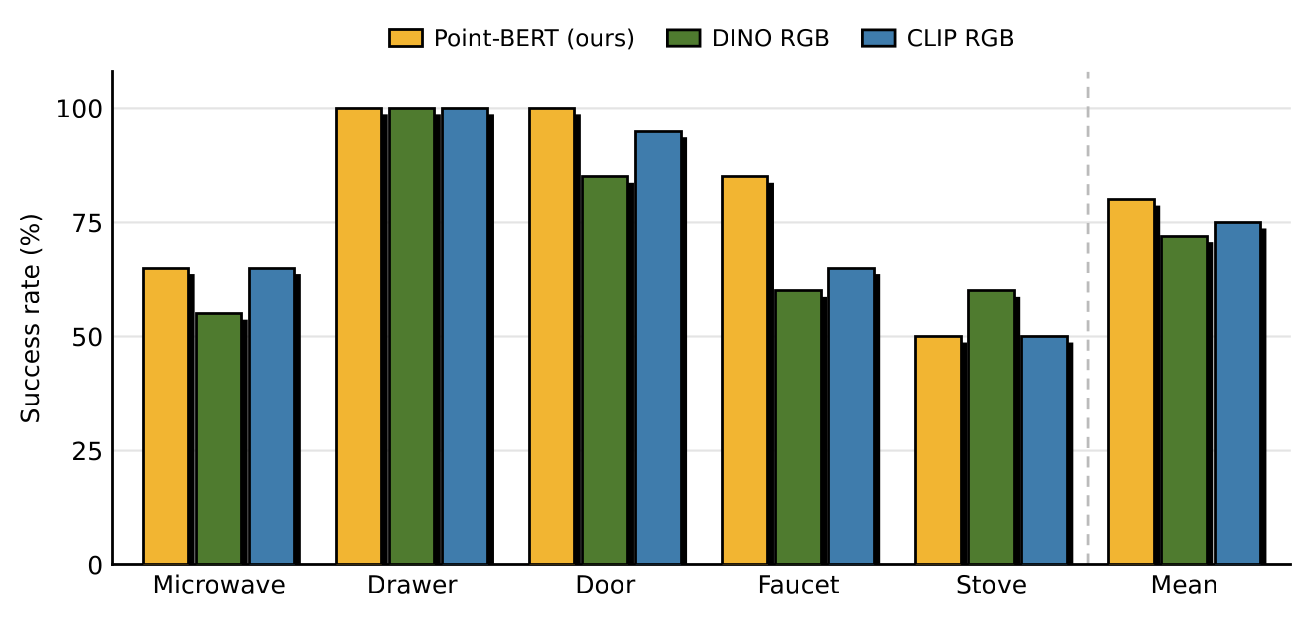
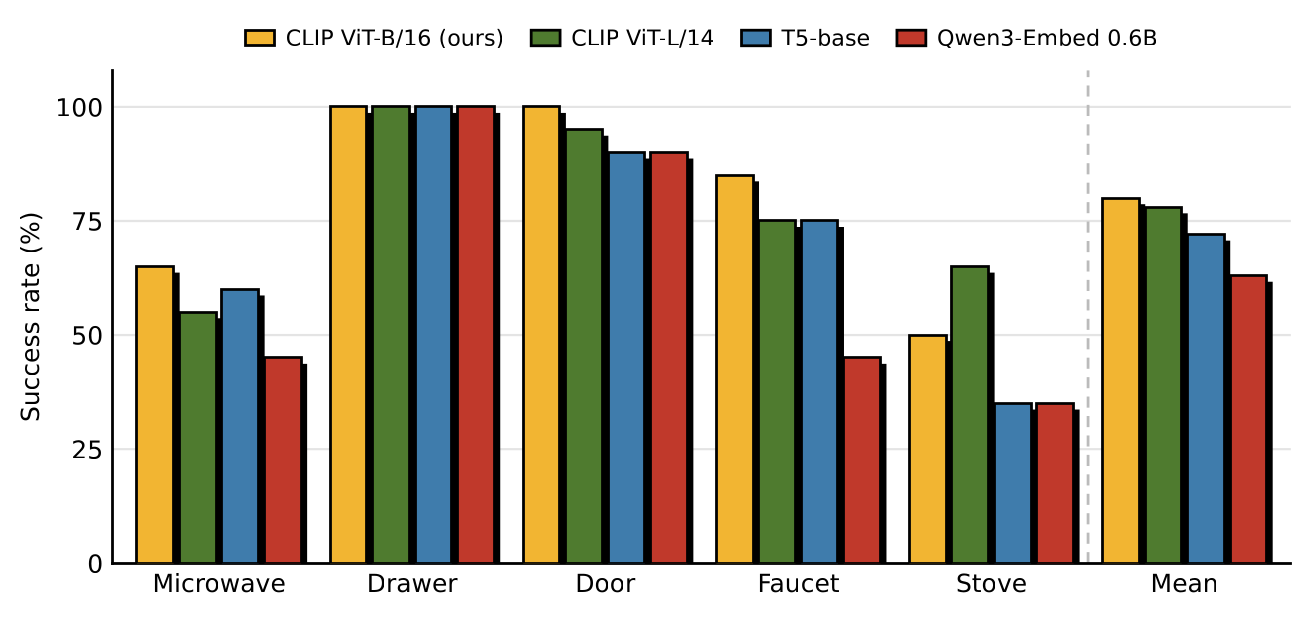
Additional encoder ablations: contrastive alignment of the text encoder to the visual stream is the dominant factor, not encoder scale — the default CLIP ViT-B/16 gives the best mean.

Deployed on a Toyota Human Support Robot (HSR) with a head-mounted RGB-D camera, MoFlo is evaluated on three tasks — Pick, CloseDrawer, and PushShelf — of which the first two require disambiguation among same-type candidates. As in simulation, an upstream image-based retrieval module brings the robot to a query pose before MoFlo predicts the base pose and a fixed manipulation policy executes. MoFlo reaches the correct base pose and completes the manipulation on all three tasks, outperforming Mobi-\(\pi\) on every task in both navigation and manipulation (e.g. 80 vs. 60 navigation and 50 vs. 30 manipulation on Pick), while a human upper bound confirms the policy is reliable once the base is well placed.
@inproceedings{anonymous2026moflo,
title = {MoFlo: Language-Conditioned Flow Matching for Policy Mobilization},
author = {Anonymous Author(s)},
booktitle = {Proceedings of the Conference on Robot Learning (CoRL)},
year = {2026},
note = {Under review}
}